


Do’s, Don’ts, and Gotcha’s from working with Amazon SageMaker & AI (Get started with MLOps)
Hello friends! Welcome back to another blog post on the Tech Stack Playbook post, your guide to apps, software, and tech (but in a fun way I promise)!
I've been diving quite a bit into AI (Artificial Intelligence) as of recent, mainly on the ML (Machine Learning) side and the data pipeline side. Between the MLOps (Machine Learning Operations) pipeline side of things, and the app configuration standpoint, it really stems down to a few core areas, with a heavy focus on cleaning, processing, transforming, and generating data. That being said, ML pipelines become very complicated as the business use case(s) expand and MLOps pipeline(s) must be maintained to meet growing end-user requirements which could be both known and unknown.
Today, I will be sharing more with you about this side of tech, specifically AI and machine learning in production. I gave a talk this past week to the Boston AWS User Group, where I shared my journey through building AI and MLOps pipelines with Amazon SageMaker. And I, as I'm sure you have been too, following all the AI news, and my journey in AI actually started last year, kind of a little bit before the ChatGPT, OpenAI, LLM (Large Language Model) hype.
From a data perspective, implementing AI might look like this:
I have a clearly defined outcome, which is our “GOAL”
I will be taking in, generating, processing, or using “DATA”
I will use this information to then generate a valuable (hopefully) “OUTPUT”
If you want to skip ahead and go right to my YouTube video 😊, check out the content here or in the embedded video below:
Do’s, Don’ts, and Gotcha’s from working with Amazon SageMaker & AI (Get started with MLOps)
In this video, I share my journey into AI and ML with Amazon SageMaker, as well as share the presentation I gave to the AWS Boston User Group. Check out the video below to tune into this episode of the Tech Stack Playbook®:

Why OpenAI, Hugging Face, and Google Have Changed the Trajectory of AI Forever
This data pipeline for AI models is something that I’ve been looking at quite a bit because we see apps like ChatGPT, HuggingFace’s HuggingChat, Google Bard, and these very sleek chat interfaces allow us to communicate with a type of machine learning model called LLMs (Large Language Models), which are trained on some billions of parameters (aka tons and tons of data, information, and references). You can then communicate with these interfaces, as directly as speaking with an AI model, but it doesn’t feel like you’re communicating with a block of code. It seems like a really smart person. And it is. These are LLMs.
This direct exchange, question and answer style, with an AI model in this way has never been achieved on a scale as big as it has become right now. This is unprecedented.
It’s been very exciting to watch the evolution of this field of AI and see how far Large Language Models and MLOps in general and those pipelines are going. Now, the ability to simply talk to the Internet directly is more accessible than it ever has been before. We can have general conversations with the smartest models on the planet, right from our phones. How cool, right?
3 Steps for Getting Started with AI & ML
Step 1: Start Using an LLM
In my talk, I introduced three core areas that you can start working on right now to build with and use AI. The first step, which is probably the one with the least barrier of resistance, is using a Large Language Model. So, what you could do is load up ChatGPT, Google Bard, or HuggingFace’s HuggingChat, and start talking to it, asking it questions, and seeing what all the hype is about.
Below are three examples of what these LLM-based chat interfaces look like. Each has it’s own, unique visual design with 3 separately trained models totaling billions of parameters in the model trainings:
OpenAI’s ChatGPT

Google’s Bard

HuggingFace’s HuggingChat

You'll learn quite a lot about how large language models are structured based upon different answers that you ask the chat interfaces. Not only can you learn from LLMs by asking them questions, as it is analogous to asking the internet directly for something, but also you can pick up on patterns in how it responds based on:
Context: adding more or less information about what you are looking for
Direction: telling the model to prioritize or focus on something specific
Intention: giving the model information about what its response should look like
Expansion: feed the LLM new information past its training (i.e. ChatGPT is only trained up to 2021)
An important point to highlight though, is that if you ask the same question to a large language model in different prompts, you will probably get different responses. That's where you need to be a little bit careful about not using large language models for quantitative data back, where you need to work with and retrieve a standardized, and repeatable, number output.
Let's say that you are scoring something like you're scoring essays, social media posts, or text messages, and you need to evaluate them with a certain sentiment score. You want to know the sentiment of each item, whether it's a happy post, if it's an angry post, if it's a confused post, if it's an anxious post, and so on. You wouldn't necessarily want to use a large language model for that because you could probably give the same or similar inputs and then get potentially drastically different responses back each time from the LLM. You would want a more standardized way where if given an input, get an output like a function.
That's where large language models are interesting because they become very creative about how they give data back to users, but you don't want to necessarily use that for numeric responses if that's a requirement. There's a lot of cool ways where you can start asking large language models questions and then getting pretty interesting, insightfulf answers back.
Example
Prompt:
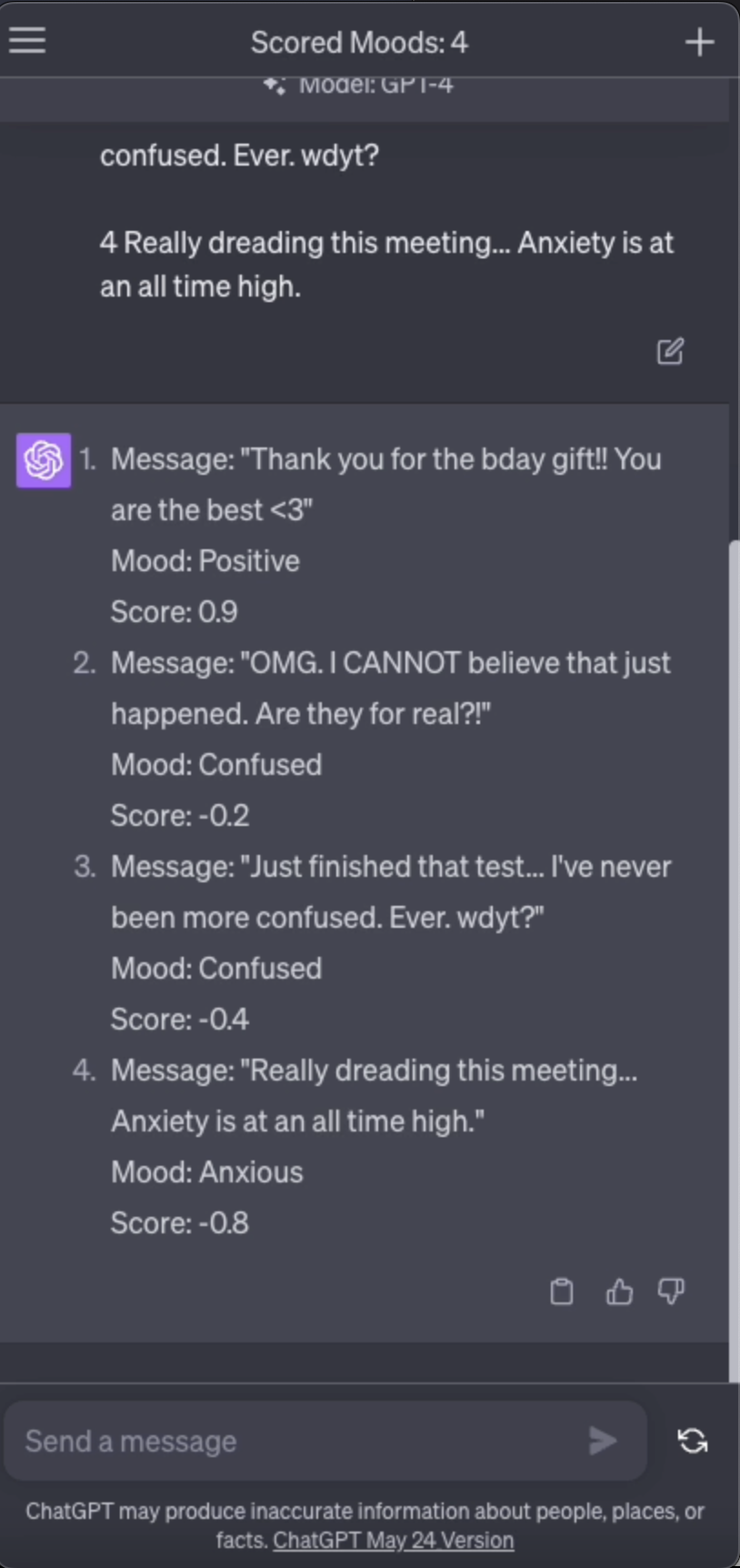
You are a social sentiment analyzer. Given a message, you will return a "mood" (i.e. Positive, Negative, Confused, Anxious) and a numeric "score" from -1 to 1. Please score these messages:
1 Thank you for the bday gift!! You are the best <3
2 OMG. I CANNOT believe that just happened. Are they for real?!
3 Just finished that test... I've never been more confused. Ever. wdyt?
4 Really dreading this meeting... Anxiety is at an all time high.
Responses (ChatGPT-4): notice the varied responses

Prompt 1 of 4

Prompt 2 of 4
Prompt 3 of 4

Prompt 4 of 4
Step 2: Start Coding with AI
The second area that I went down on the AI rabbit hole was looking at code interpreters and code generators, which led me to Amazon CodeWhisperer. It become an amazing code interpreter and basically an AI pair programming buddy in my day-to-day work. What's really interesting is that when you are using a coding tool like Amazon CodeWhisperer, you can directly integrate this technology into your favorite IDE / code editor, and now you are powered by AI. As you type, the AI is analyzing your codebase, and it’ll actually start giving back responses that are commensurate to how you actually code.
Amazon CodeWhisperer Examples Pt. 1
Generate a sum function

AI suggestion of the addTwoNumbers function

AI suggestion of the sum function using addTwoNumbers generated previously
In a really specific example, there's a way that I do comments in my code where I’ll write comments that have a commented line of “===============” before and after the title. So it becomes a 3 line block comment to help give visibility to sections of which might be seemingly endless functions, components, etc.
Amazon CodeWhisperer Examples Pt. 2
Picking up the coder’s syntax and coding conventions

After writing // ===== // on line #8, Amazon CodeWhisperer then suggested to close out the comment after the title on line #10.

As soon as I started prompting another comment with / , Amazon CodeWhisperer was already suggesting my comment construction.
Step 3: Start Building ML Pipelines
The third area that I dive into is the MLOps pipeline side, which is the full construction of AI systems, including model deployment, hyper-parameter tuning, endpoint construction, and app integration. How do these LLM chat applications work? They have built a robust MLOps pipeline that not only drives business value, but constantly allows for updates, modifications, training of new data and inputs, and autoscaling based on demand.
What does a full MLOps pipeline look like? Here is an example:

With Amazon SageMaker, so much of this complexity is abstracted away with a programmable dashboard and toolchains to work with data, process data, train the model with new data, test outputs, and more.
Now combine the multiple flavors of SageMaker together and now you can run full MLOps pipelines at scale depending on your use-cases and requirements.

How to Start Using Amazon SageMaker
Set up a SageMaker Domain
To start working with Amazon SageMaker Studio, we will first need to set up a SageMaker Domain and a corresponding IAM role.

When we set up a domain for the first time, we will need to create an IAM role with the right levels of access to connect with other AWS services. For example, we might need SageMaker to be able to read/write to Amazon S3 if we are fetching or storing datasets in our pipelines.
This is all done through AWS’ Role Creation Wizard when we set up the SageMaker Domain. If you would like to enable SageMaker Canvas, you can select this option.
You will also need to set up a VPC with a public and private subnet to operate in a private cloud and also connect to the internet should that be required for pulling any outside information or resources into AWS.
Running Amazon SageMaker Studio
The Amazon SageMaker Domain can take up to 15-30 minutes to create, but then once the domain is activated, you can launch the Amazon SageMaker Studio.
This might take 5-10 minutes to load up as the virtualized Jupyter Notebook environment will need to be constructed, but once it’s live, you will have the full power of Amazon SageMaker at your fingertips.

Use-Cases for Amazon SageMaker
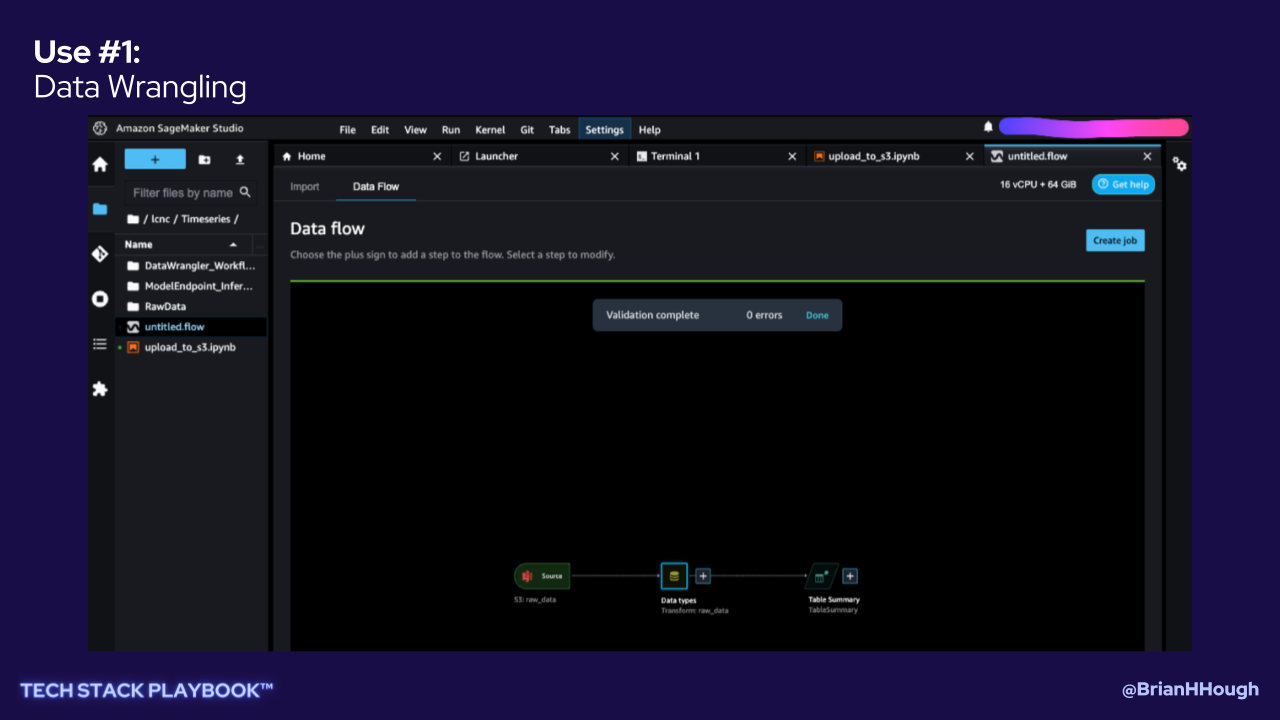
Use #1: Data Wrangling




Use #2: Data Transformation




Use #3: Data Visualization


Use #4: Data Generation




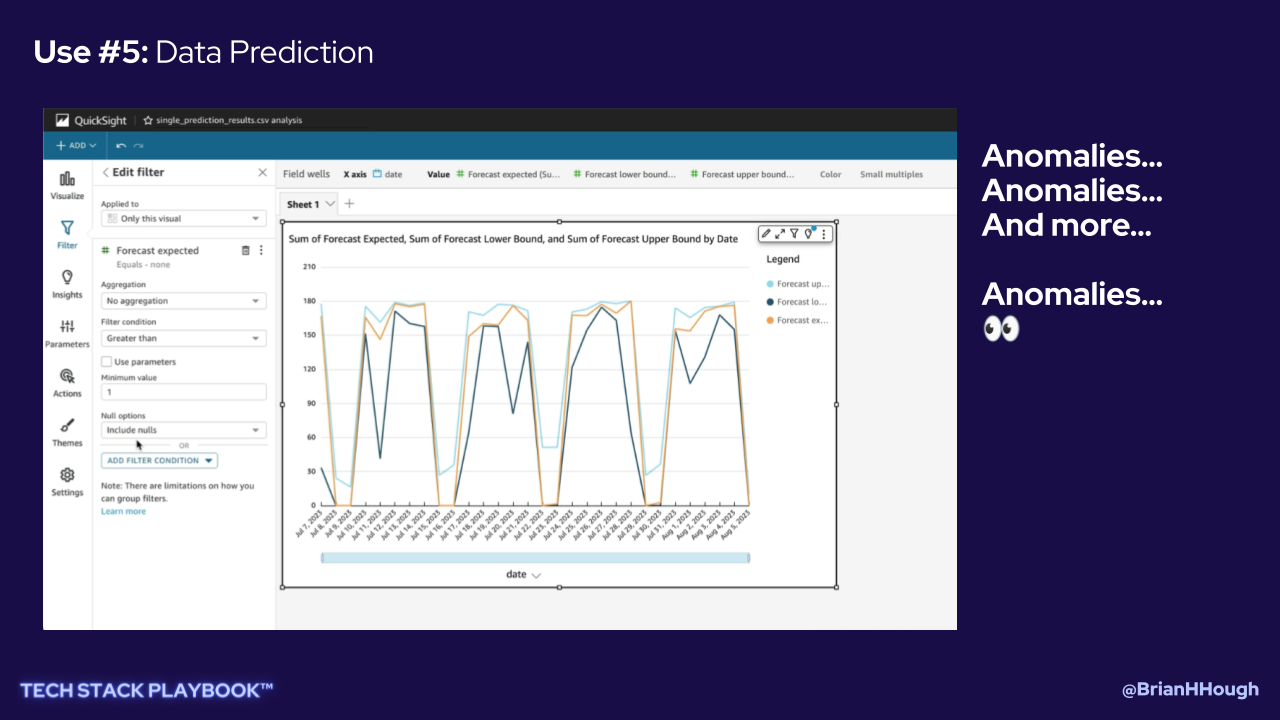
Use #5: Data Prediction







Resources for learning more
When thinking about MLOps, there are two flavors I’ve been looking at frequently.
Amazon SageMaker Studio: a virtualized Jupyter Notebook experience with AWS integrations, plugins, and toolchains.
Amazon SageMaker Canvas: a low-code/no-code UI for using different models for data prediction, data generation, and more.
Two very helpful workshops for traversing these two flavors of SageMaker that I often point to for learning MLOps are:
Generative AI & Data Science with Amazon SageMaker on AWS - Workshop — a Generative AI on SageMaker workshop based on Chris Fregly and Antje Barth's "Data Science on AWS" O'Reilly book.
How To Build Stock Price Prediction Without Writing a Single Line of Code — a comprehensive tutorial by Viktoria Semaan on how to use NASDAQ stock data with Amazon SageMaker Canvas to predict the price of stocks using AI without a single line of code.
Generative AI & Data Science with Amazon SageMaker on AWS - Workshop

How To Build Stock Price Prediction Without Writing a Single Line of Code
I believe the future of AI is an exciting one that everyone should have a chance to be a part of. So, whether you're a newbie, an enthusiast, or an expert in the tech field, this video will bring you valuable knowledge that you can start implementing today.
Jump right in and let's explore the exciting world of AI and MLOps together! 🚀
Subscribe to the Tech Stack Playbook® for more content:
Listen on Spotify:
Links
Let’s Connect Online:
☕️ By me a coffee to support my channel: https://buymeacoffee.com/brianhhough
📲 Let's connect on Instagram: https://instagram.com/brianhhough
🤝 Let's connect on LinkedIn: https://linkedin.com/in/brianhhough
🌟 Check out my other episodes: https://www.brianhhough.com/techstackplaybook
📚 Take my FREE 3-Hour Solidity & Web3 Course: https://youtu.be/il9s98lPGqY
Get Some Cool Stuff:
*These affiliate links are commission-based
👨💻 Codecademy — get a FREE MONTH of a Pro membership: http://ssqt.co/mQgVi7z
✨ Upgrade your workspace — check out my workspace essentials on Kit.co: https://kit.co/BrianHHough/workspace-essentials
💰 Coinbase — get $10 FREE of Bitcoin: https://coinbase.com/join/hough_7?src=ios-link
💸 Robinhood — get a FREE stock: https://join.robinhood.com/brianh4666
📇 Unstoppable Domains — get a FREE blockchain domain name: https://unstoppabledomains.com/?ref=5ef8
📈 Kajabi — get a $150 credit (free month) to launch your online digital business: https://app.kajabi.com/r/dAczTf9d
🖥 Autonomous.ai — build a smart workspace with a FREE $25: https://bit.ly/38REicE (or use code R-bhh210)