


How to Prevent Caching on Fetch Requests to An API (Squarespace + Vanilla JS)
Something strange that I noticed when I was trying to implement pagination for my Squarespace blog was this weird, what I thought was, a legacy caching behavior from my old code.
Upon further inspection, I learned that I was able to query a blog with this construction:
curl -s 'https://name-here.squarespace.com/blog-name-here/?format=json-pretty' | jq '.collection.categories'
This will pass back an array of categories related to your blog.
❌ Regular browser session not working
That being said, I was using this construction in my api request, and I kept getting this response - the categories of my old data:

✅ Incognito browser working 🧐
There are supposed to be many more pages here… and when I went to an incognito browser window, I saw all of the categories for my blog:
Testing Cache-Busting in the terminal
In case the browser is caching an older version of the json-pretty output, I implemented a cache-busting technique of appending _= with the current timestamp to avoid cached data and fetch unique data every time.
To test this, I ran the following code in my terminal:
curl -s "https://name-here.squarespace.com/blog-name-here/?format=json-pretty&_=$(date +%s%3N)" | jq '.collection.categories'
Method #1: To implement this with Vanilla JS, I wrote this to fetch the data without caching:
fetch('/name-here.squarespace.com/blog-name-here/?format=json-pretty&_=' + new Date().getTime())
.then(response => response.json())
.then(data => {
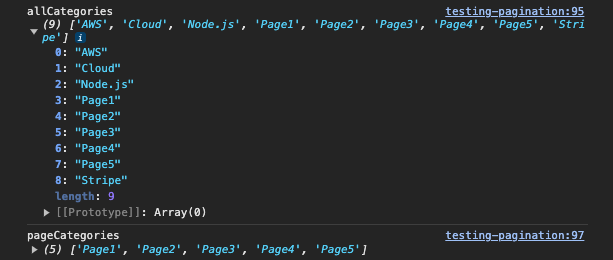
const allCategories = data.collection.categories;
console.log('allCategories', allCategories)
const pageCategories = allCategories.filter(category => category.includes('Page'));
console.log('pageCategories', pageCategories)
const totalPages = pageCategories.length;
console.log('totalPages', totalPages)
})
.catch(error => console.error('Error fetching categories:', error));
}
In this code, I am appending the Date().getTime() to generate unique fetches for the blog JSON data and then this enforces a non-caching policy.
Method #2: To implement this with Vanilla JS, I wrote this to fetch the data without caching:
fetch('/name-here.squarespace.com/blog-name-here/?format=json-pretty', { cache: 'no-cache' })
.then(response => response.json())
.then(data => {
const allCategories = data.collection.categories;
console.log('allCategories', allCategories)
const pageCategories = allCategories.filter(category => category.includes('Page'));
console.log('pageCategories', pageCategories)
const totalPages = pageCategories.length;
console.log('totalPages', totalPages)
})
.catch(error => console.error('Error fetching categories:', error));
}In this code, I am appending the { cache: 'no-cache' } no-cache directive to the fetch function in order to inform the fetch function that the data fetched should be unique and impartial to fetching. This method is my personal favorite and I find easier to conceptually implement than time stamps, but in case this method does not work, the Method #1 is an option as well.
🥳 The finished solution
At long last, we finally have a way to fetch unique items without worrying about data that may or may not be cached, and it is very fast. If all goes well, you will see your un-cached, complete, data here:
